



One of the most interesting research trends in LLMs right now is the rise of reasoning models which spend time “thinking” before giving you an answer. OpenAI o1 is the predominant public LLM doing this today, though Deepseek R1 and Qwen QwQ are other notable recent releases in this domain as well.
This technique is broadly described as “test-time” compute—i.e. reasoning at inference time. While the idea of models which apply search or deeper reasoning at inference has been around for a while—e.g. AlphaZero, this paper applying similar ideas to the traveling salesman problem before transformers were a thing—it has sort of re-entered the zeitgeist with o1.
What seems particularly exciting is that this form of test-time compute may demonstrate similar scaling laws as pre-training—in other words, there is a theoretically predictable exponential increase in model capabilities as you allocate more compute during inference time before giving an answer, just as there has been a predictable exponential increase in model capabilities as you train them with more compute.
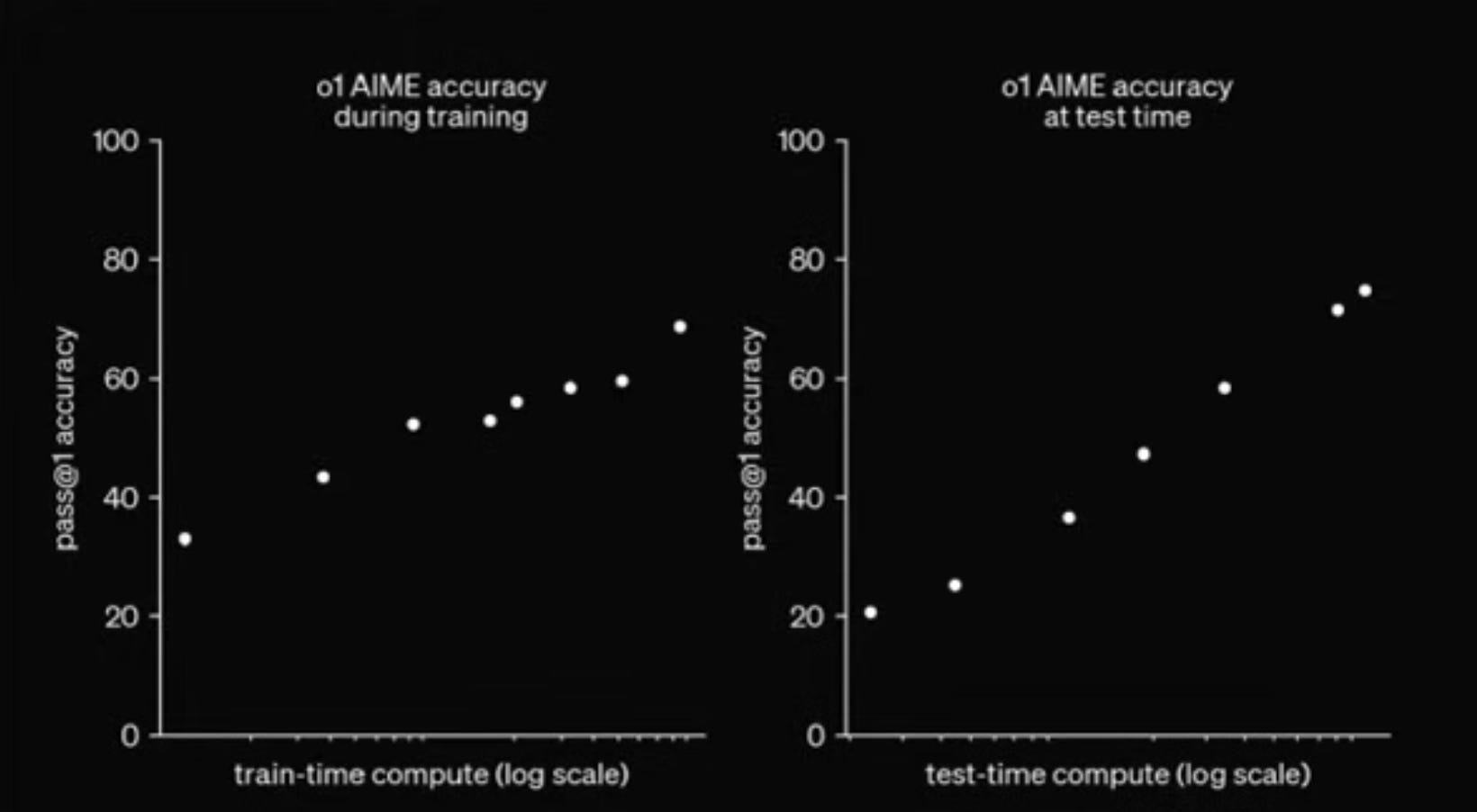
But, what is actually happening under the hood for models like o1 to do this, and what are the different mechanisms or techniques by which test-time compute scaling can be achieved? I have not found a good, intuitive overview of this anywhere, and OpenAI is tight lipped about what exactly they're doing, so this is my attempt to create one.
In this blog I aim to outline the major ways test-time compute scaling can be achieved, based on both reviewing a lot of the recent literature in this space as well as talking to a number of ML researchers at research labs.
Have a language model generate many possible outputs during inference time, and then use some kind of sampling, voting, or other evaluation/verifier methodology to pick the “top” answer. This is a simple idea that requires essentially no changes to how the model is trained, but does seem to be an effective baseline.
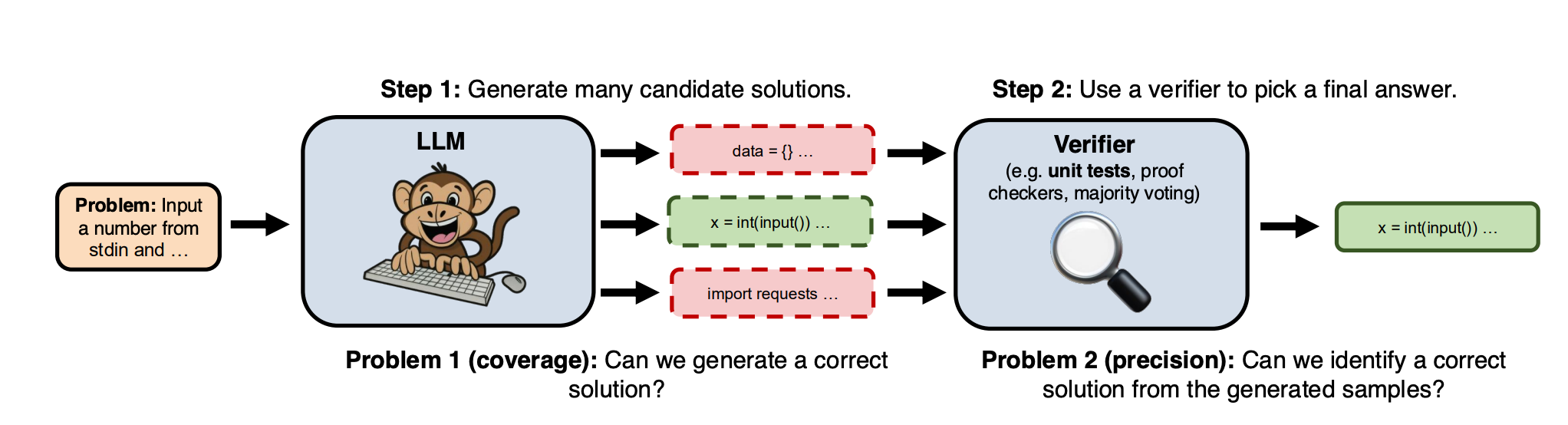
The first nuance here is in the verifier. Simple approaches like majority voting generalize well but have limits in their utility. Specific domains like coding or math have specialized verifiers that can be used (e.g. unit test and compilers for code, symbolic engines for math), but these are not general purpose. An increasingly common technique is fine-tuning an LLM to be a specialized verifier—e.g. see here.
The other issue is that it is likely that for many more complex problems, no matter how many times you sample a “standard” model, you will not get the right answer (or it will take an unfeasible amount of compute to generate the right answer at a sufficiently high probability). As we will see, the right way to solve this is likely to either train on better reasoning traces, or to have a reward process that can help “nudge” the model through a complex reasoning trace.
The second approach is to have the language model generate a very long, detailed chain of thought reasoning trace as a way to improve reasoning capabilities. This is just a single model auto regressively producing a lot of tokens as it, essentially, talks to itself - there is no secondary system or control flow. OpenAI shows examples of this in its o1 announcement.
While a basic version of this can be achieved via prompting (e.g. “think step by step”), the advanced version of this involves specialized pre-training and post-training techniques which optimize for these sorts of long reasoning traces.
The nuance here is in how exactly the models are trained to be better at these long reasoning traces. Roughly, there are a few ways of achieving this:
The critical consideration here is what scales in terms of 1. data 2. computational feasibility and 3. human labor? The fact OpenAI mentions their o1 technique is “data-efficient” is a representation of the fact that they likely are heavily relying on some combination synthetic data and RL-based verification techniques, as opposed to some kind of human-curated reasoning dataset.
Synthetic techniques can be effective but tend to be limited to specific domains and types of problems that are more easily quantifiable - as such there are questions about how well they generalize.
The challenge with sampling techniques is that the computational search space of reasoning for many interesting problems is too large to exhaustively generate and very complex to efficiently validate. This makes it look a lot like other areas of reinforcement learning, like robotics, where you need to get clever on how to simulate or “search” the space of outcomes and how you design reward functions.
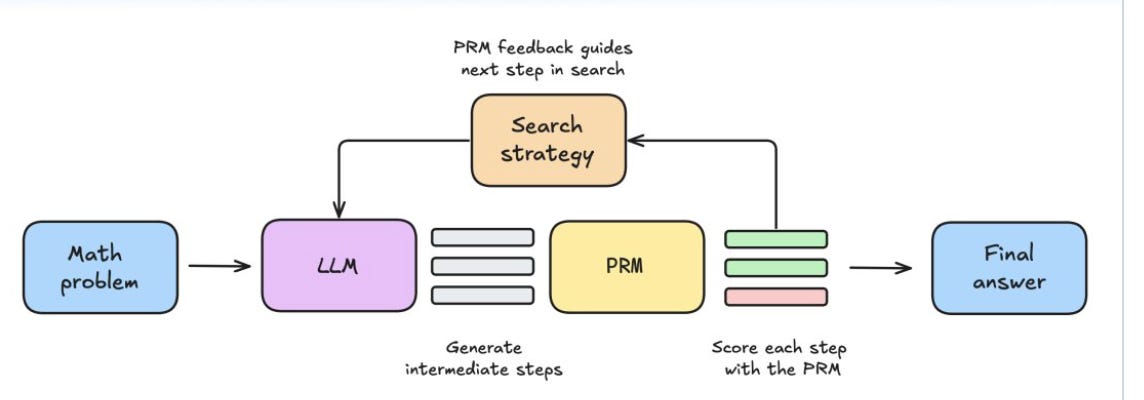
This is the critical driver of why process reward models are interesting - they allow you to terminate solutions early which are on the wrong track, and focus on branching out from intermediate states with high likelihoods of success (good discussion of this in section 3.3 here).
There are a lot of interesting explorations on the right way to structure reasoning traces for effective training. For example, Dualformer selectively obfuscates parts of reasoning traces during training in order to (theoretically) help the model learn mental heuristics analogous to fast, system 1 thinking in humans. Stream of Search highlights potential benefits of having reasoning traces which make a lot of mistakes (e.g. include backtracking, admitting mistakes, changing your mind) as opposed to “perfect” reasoning traces towards a conclusion. This paper similarly demonstrates the value of having mistakes and poor reasoning chains with backtracking in a training set. Beyond A* tries to teach models how to search by constructing training examples which replicate well known search algorithms like A*.
The third major approach for inference-time scaling is to actually utilize some kind of search technique during inference time. In other words, inference becomes a systems problem, not just a model inference problem, and you have some kind of control flow or orchestration at inference time as opposed to a single model purely generating token output.
Some interesting examples of this paradigm outside of “standard” large language models include AlphaZero, where a trained neural network guides a Monte Carlo tree search algorithm to select the best next move, and AlphaProof, where a pre-trained large language model + RL algorithm generate solution candidates which are then proved or disproved with the Lean proof assistant language.
The most common variation of this in LLM research today is to integrate some kind of “search + verify” technique at inference time - where the model generates a set of N candidate next steps of reasoning, a verifier or reward model is used to grade or score or invalidate those candidates, and then the process is repeated among a subset of the best candidates. Note that you could consider the “Best of N” sampling approach discussed earlier as a sub-set of this.
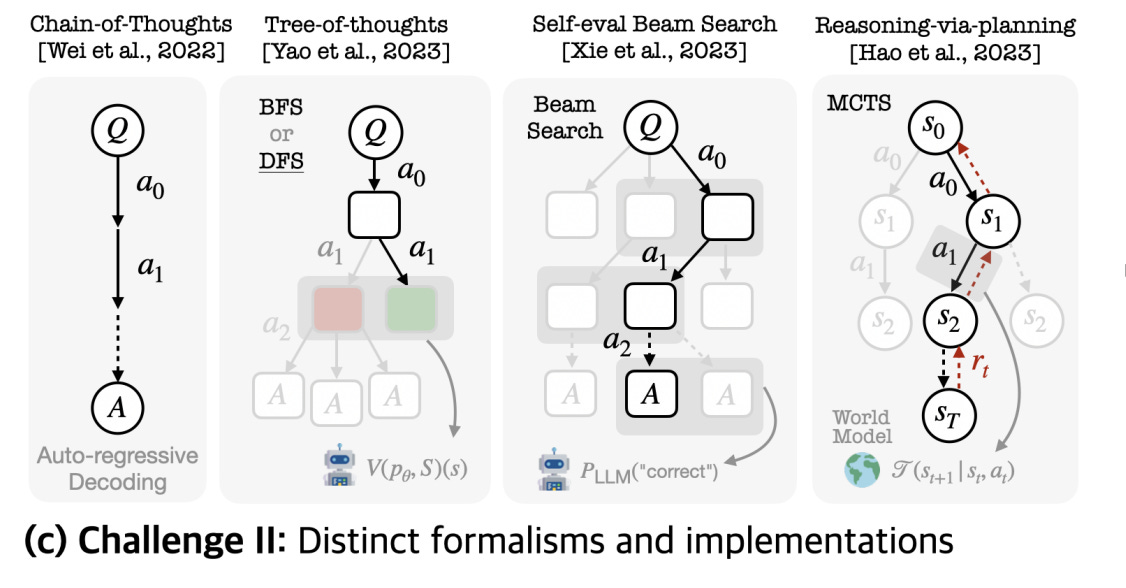
Good research examples of this include Tree of Thoughts, Self-Evaluation Guided Beam Search for Reasoning, and Reasoning with Language Model is Planning with World Model - each of which utilizes a search technique (breadth first search, depth first search, beam search, Monte Carlo tree search) coupled with a verifier to guide the language model reasoning generation. I like the visual depiction of these in the LLM Reasoners paper shown below. Conceptually, all of these ideas & approaches are very similar.
You’ll note that this approach of search + verifier + generative model is almost identical to the approach outlined in the chain of thought section above - the only difference is whether these techniques are applied offline to produce post-training RL datasets or applied online during inference time. In either case, however, you are scaling with test-time compute - the former teaches the model to reason longer at test time via training, and the latter guides the model over a larger set of generative outputs during inference time.
Beyond using search algorithms to guide generation, there are other types of secondary systems that can be integrated at inference time which complement the generative model. The RAP paper is a particularly interesting example of this - where they use a secondary LLM as a “world model” which tracks the state of the environment. In other words - as the generative LLM is producing a continuous stream of reasoning actions that include backtracking, thinking, consideration, etc, the world model tracks the “state of the world” at the end of each possible action.
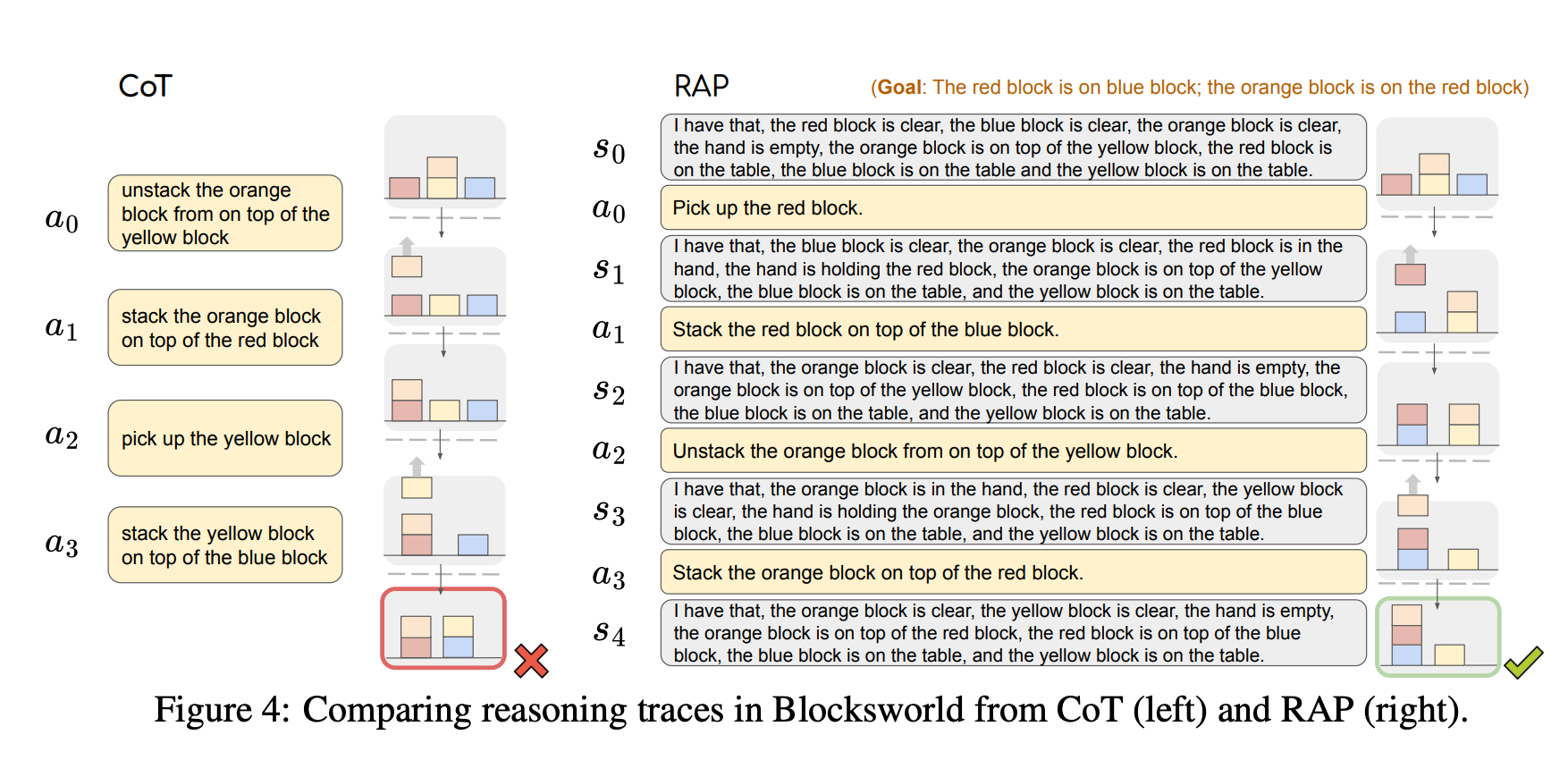
In theory, this makes it easier for the model to reason about the impact a subsequent next action will have, relative to a single stream CoT output where the model must implicitly playback the sequence of actions to understand the current state of the world.
_
The reasoners papers mentioned above posits an interesting formalism for trying to unify all these different approaches and ideas (e.g. majority voting, CoT, search techniques, etc).
They argue that all these techniques are ultimately a combination of:
In this framing, standard chain of thought reasoning has a reward function equivalent to the default model likelihood output, a world model that is just a constant appending of reasoning actions to a full action history, and a “greedy” search algorithm that always does a single sample of the output probability distribution.
I find this to be an interesting way to think about the space. The paper also does some interesting benchmarking and finds that search techniques consistently beat CoT, and RAP (world model + search) consistently beats pure search.
This recent meta overview by Stanford of reasoning models describes a similar mental model - arguing most of these approaches are “integrating generator, verifier, and search components”, which is essentially the same framing.
As you can see, a lot of this hinges on verifiers and the quality of verification. Heuristic/automatic verifiers can be effective but definitionally are domain specific (e.g. test cases for coding questions). Learned verifiers can work, but require high quality training data in the given domain - e.g. see this early OpenAI paper which trains learned verifiers for math problems. There is a lot of progress on simply using LLMs as verifiers, but there may be limits to what is feasible with this. Process based verifiers seem important to get right, but are more difficult to design than outcome based verifiers.
MuZero is an interesting reference point for where this space likely needs to go - it is a model-free reinforcement learning based system that can learn to play a wide variety of complex games at an elite level. Model-free means nothing is encoded about the specific game it is playing in the RL algorithm.
This sort of domain-independent verifier design seems critical for models to get generally better at reasoning. Of course, the question is the extent to which this can be mapped to domains with less clear reward functions than Go, chess, shogi & Atari.
This is an excellent blog post discussing the challenges with applying RL for reasoning, specifically in the context of OpenAI o1.
o1 uses RL, RL works best in domains with clear/frequent reward, and most domains lack clear/frequent reward.
…
OpenAI admits that they trained o1 on domains with easy verification but hope reasoners generalize to all domains. Whether or not they generalize beyond their RL training is a trillion-dollar question. Right off the bat, I’ll tell you my take:
⚠️ o1-style reasoners do not meaningfully generalize beyond their training
Anecdotally, it does seem like many of the current test-time compute models are a lot better for very specific problem spaces (math, logic, computer science), but don’t seem dramatically better in other domains. Indeed, many folks I speak with who have tried these test-time compute models anecdotally feel that they get a lot worse at many conventional or standard generative tasks. Whether or not RL for reasoning can generalize well to harder-to-verify domains is an interesting open question.
Somewhat orthogonal to all of this is the question of whether token-space is the optimal way for a model to reason. There is some interesting research on having models reason directly in latent space - where during the reasoning period the hidden states are passed back to the model rather than the decoded token.
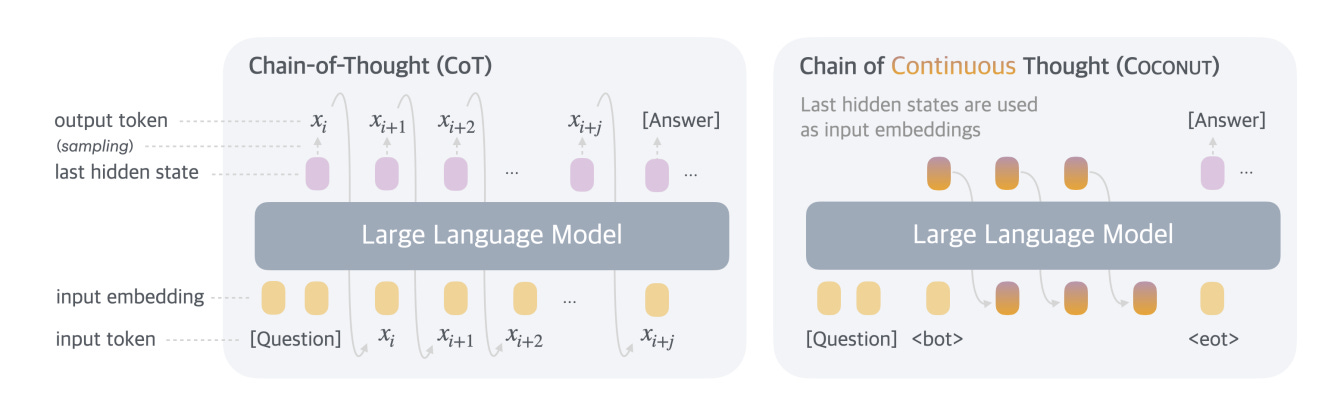
In theory, this may have advantages because the hidden state represents a probability distribution of next token generations, whereas the token is essentially a “sample” of that probability distribution, and it may be effective to reason across all possible next states vs. picking one as this mirrors how humans reason.
A potential downside of this approach is that such a model would not “show its work” to the user, though given that companies like OpenAI are already hiding their reasoning steps from the user, perhaps this is irrelevant. I suppose it may be possible to still visualize the token output but reason on the latent output, though this may create a divergence between what the user sees and how the model actually reasoned.
One thing I am particularly interested in is how all of this maps to agents. There is an extreme parallel between optimizing a model for complex reasoning trajectories that span many sub-steps, and optimizing an agent for complex reasoning trajectories which span many sub-steps. The only difference is that an agent’s sub-steps are broken up into different model calls and typically involve more moving pieces (e.g. function calling, etc).
I observe that many of the leading agent startups building agents for X (e.g. Cognition, Basis, etc) apply many of these ideas to their agent design. For example, I have spoken to multiple agent companies that take their agent traces, replay them with some kind of search technique + reward model to explore counterfactual reasoning paths, and use those counterfactual trajectories as fine tuning examples for improving their agentic system.
This approach becomes critical if you are working on an agent doing 50-100+ chained LLM calls to solve a given action in a complex environment with many tools, given the combinatorial complexity of actions the agent can take for a single request.
What I find particularly interesting about this is that it is much more feasible to design domain-specific search algorithms and process reward models than it is to generally solve complex multi-step reasoning at the model layer.
This is an interesting corollary of the blog post I mentioned above questioning if these techniques will generalize - perhaps RL for complex reasoning will be difficult to generalize well at the model provider layer, and instead will become a core competency (and layer of defensibility) for most applied agent startups in domains that require very complex reasoning to solve tasks (e.g. accounting, tax, finance, architecture, etc).
I also suspect tooling will emerge that aids agent startups with this sort of task - analogous to the ecosystem that has emerged around fine tuning (e.g. MosaicML). Such tools would make it easier to build search + verifier layers and generate datasets with them for a given applied agent use case.
_
A lot of this blog is me attempting to explain this all to myself. If you think I am missing something, let me know.